← Back to Projects

RAG Anything
Mentored by: Mobileye
Advanced multi-stage RAG system for source-grounded answers
Python
OpenSearch
Rerankers
LLMs (Gemma-3 1B/4B)
Embeddings
Vector Search
QA Pipelines
Description
A retrieval-augmented generation platform combining keyword search, OpenSearch indexes, embedding search, rerankers, confidence-aware pipelines, Wikipedia-scale preprocessing, LLM selection experiments, student/teacher distillation, and multi-stage QA flows. Includes Basic RAG, Query-Expanded RAG, Multi-Stage RAG + Reranker, and Multi-Stage RAG + Confidence. System optimized for precision/recall and scalable document ingestion.
Team Members
Cohort: Data Science Bootcamp 2025 (Data)

Responsibilities:
Finding the most efficient and accurate method for obtaining the most appropriate documents for the requested topic through trial and error research
Retrieving documents that match a query using embedding - Converting each title to a vector upon receipt of the database and upon entering a query, converting it to a vector as well and finding the documents with the closest Euclidean distance.
Running the model on the server with various queries that address different data sources to test the efficiency and accuracy of the model.
BM25 model experiment (Smart Search Model) following the disqualification of embedding Due to slow response speed and relatively large memory footprint .
Open search( open source for efficient searching in a large database using indexes)
Testing the model with various queries and parameters to find the formula to obtain a quick and highly accurate answer. Comparing accuracy and efficiency against previous models, and implementing the model in the project after it has proven to be highly accurate and efficient.
Researching the way to get the most correct answers – a broad study examining how the most correct sources of information will be reached in the shortest time using the HotpotQA dataset.
Checking the number of sources returned and trying to use a threshold that limits the minimum match score.
Data minimization to prevent server crashes after production. The minimization is performed before the data is entered into the LLM model to obtain the answer.
Improved user experience in React UI such as user access to the information sources from which the answer was drawn
The sources were saved and returned to the UI to be displayed to the user
Responsibility for server maintenance, user management, and resource distribution between teams - and limited storage space for two AI teams, as well as smart use of the available memory.
...and more contributions not listed here
Responsibilities:
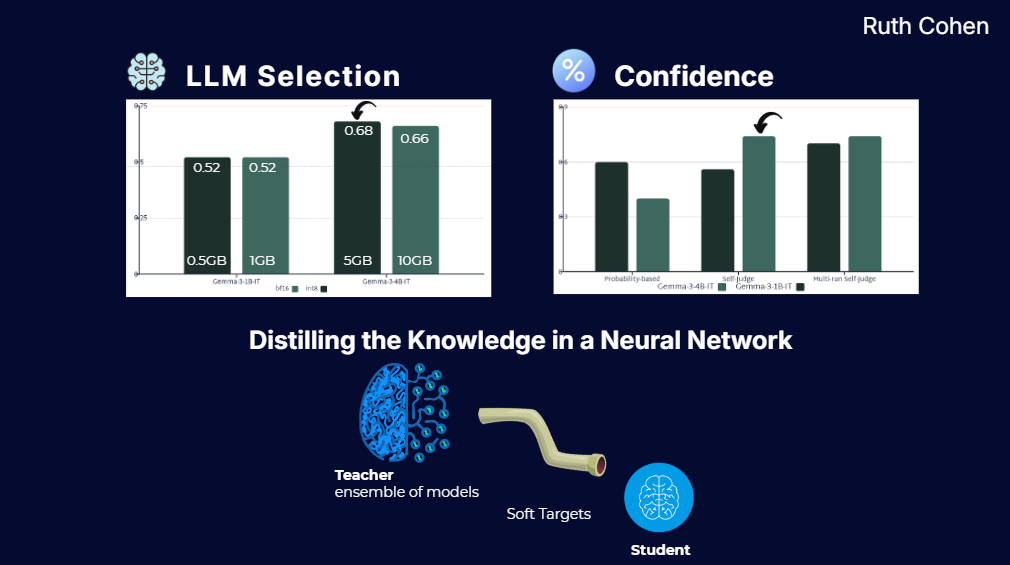
LLM Model Selection: Evaluated and compared multiple LLMs with a focus on local inference constraints and performance trade-offs. Selected Gemma3-4B as the core model for RAG interaction and response generation.
LLM Communication Microservice: Built a Python microservice for efficient LLM interaction and model loading using HuggingFace Transformers.
Resource Optimization and Efficient Inference: Evaluated multiple quantization approaches and chose int8 to balance performance, memory efficiency, and response quality.
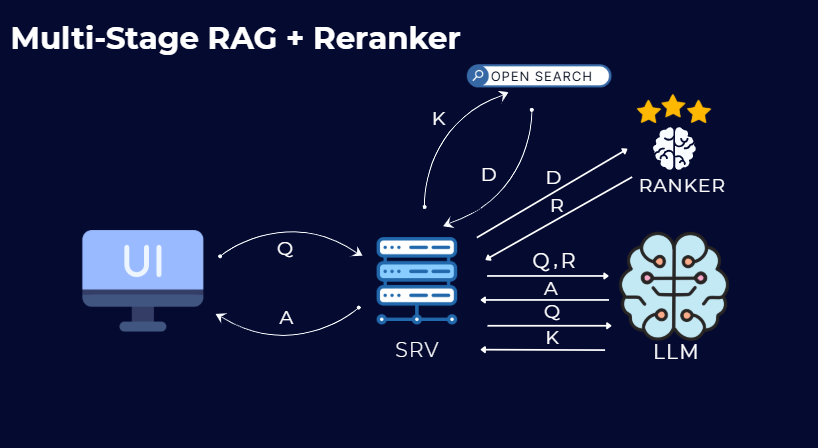
Retrieval Ranking Optimization: Used a ranker model to focus retrieved documents, improving answer accuracy and reducing memory usage significantly. Enhanced alignment between the retrieval stage and LLM-based response generation.
Design and implementation of a confidence for LLM responses: Researched multiple methods and applied a self-confidence approach to produce a weighted confidence score alongside answers.
Model deployment and resource optimization Evaluated and configured models for efficient local execution, balancing CPU/GPU usage, memory, and inference performance.
Research on knowledge distillation in neural networks: Reviewed and analyzed the paper Distilling the Knowledge in a Neural Network, presented insights to the team, and explored implementation ideas within the system.
User-specific functionality and UI enhancements: Implemented per-user features, including file upload capabilities for the RAG system, and adapted the user interface accordingly.
...and more contributions not listed here
Responsibilities:
Designed and implemented a clean, intuitive UI for the RAG Anything system, enabling seamless interaction with the retrieval-augmented pipeline and improving overall user experience.
Research: prototype development for a personalized chatbot-alignment feature, exploring RLHF methodologies, evaluating HH-RLHF datasets, and fine-tuning Qwen models using TRL DPO to learn user-specific preferences through real-time feedback signals.
Developed and evaluated query- and document-expansion strategies to improve semantic search accuracy, including generating expansion candidates with Gemma, enriching the knowledge graph with AI-domain question variations, and testing search performance across easy and hard real-world queries (e.g., technical, keyword-based, and time-sensitive questions).
Designed and built the main server architecture using FastAPI, including full message-history management, asynchronous microservice communication, well-structured Pydantic models, custom middleware for logging and validation, and coroutine-based request handling to ensure scalable, high-performance operation across the entire RAG system.
Deployed the main server and UI to production infrastructure, configured secure SSH-based server access, and integrated the frontend with the backend through Cloudflare routing. Ensured successful end-to-end connectivity, validated deployment stability, and delivered a live UI endpoint for team testing.
Evaluated LLM performance over the MMLU benchmark by loading and filtering the dataset, generating chain-of-thought answers for 1,531 validation questions measuring accuracy and latency distribution, and comparing model performance with and without retrieval-based search. Implemented prompt-engineering improvements (e.g., reasoning-first format) and analyzed representative examples to assess quality and failure modes.
Conducted LLM evaluation experiments on Natural Questions and HotpotQA datasets by prompting Gemma-3-1B and Gemma-3-4B to score question-answer pairs. Implemented multiple scoring strategies, including single-pass and averaged multi-pass ratings, analyzed outputs manually for 10+ examples to ensure reliability, and compared model accuracy across configurations.
Implemented user-specific features in the RAG Anything UI and backend, including login with message-history persistence, document upload to named indices, and dynamic index selection for searches. Updated user database to track custom indices, integrated backend routes to handle document ingestion and indexing in OpenSearch, replaced static defaults with dynamic UI-driven values, and performed end-to-end testing of both frontend and backend components.
...and more contributions not listed here

Responsibilities:
Downloaded and processed the full Wikipedia dump to generate a clean, searchable default index. Implemented text extraction, cleanup, and JSONL generation to support large-scale indexing in OpenSearch.
Designed and implemented the user-specific indexing system, including the ability to create personal indexes and upload multi-format documents (PDF, DOCX, TXT). Developed the backend pipeline responsible for file processing, text extraction, normalization, and ingestion into OpenSearch.
Built a dedicated voice-processing server enabling audio-based queries. Integrated Whisper for speech-to-text transcription and connected the service to the chat interface, allowing users to submit questions directly via microphone.
Research: Text-to-speech microservice using FastAPI and Coqui TTS for generating spoken answers from the chatbot.
Research: LoRA fine-tuning of Gemma-3-1B on HotpotQA to train a model that predicts relevant Wikipedia titles. Implemented dataset preparation, quantized model loading, SFT training, and an evaluation pipeline (precision/recall/F1).
...and more contributions not listed here